











大家做seo都是在千方百计的让搜索引擎抓取和收录,但是其实很多情况下我们还需要禁止搜索引擎抓取和收录
比如,公司内部测试的网站,或者内部网,或者后台登录的页面,肯定不希望被外面的人搜索到,所以要禁止搜索引擎抓取。
禁止搜索引擎抓取方法:
创建robots.txt文件到WEB根目录下,其内容为:
|
User-agent: Baiduspider
Disallow: /
User-agent: Sosospider
Disallow: /
User-agent: sogou spider
Disallow:
User-agent: YodaoBot
Disallow:
User-agent: Googlebot
Disallow: /
User-agent: Bingbot
Disallow: /
User-agent: Slurp
Disallow: /
User-agent: Teoma
Disallow: /
User-agent: ia_archiver
Disallow: /
User-agent: twiceler
Disallow: /
User-agent: MSNBot
Disallow: /
User-agent: Scrubby
Disallow: /
User-agent: Robozilla
Disallow: /
User-agent: googlebot-image
Disallow: /
User-agent: googlebot-mobile
Disallow: /
User-agent: yahoo-mmcrawler
Disallow: /
User-agent: yahoo-blogs/v3.9
Disallow: /
User-agent: psbot
Disallow: /
|
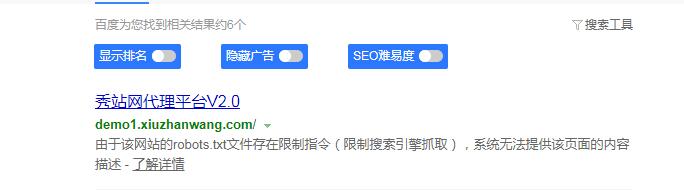
给大家发一张禁止搜索引擎抓取网站的搜索结果截图:
百度官方对robots.txt的解释是这样的:
Robots是站点与spider沟通的重要渠道,站点通过robots文件声明本网站中不想被搜索引擎收录的部分或者指定搜索引擎只收录特定的部分。
9月11日,百度搜索robots全新升级。升级后robots将优化对网站视频URL收录抓取情况。仅当您的网站包含不希望被视频搜索引擎收录的内容时,才需要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。
如您的网站未设置robots协议,百度搜索对网站视频URL的收录将包含视频播放页URL,及页面中的视频文件、视频周边文本等信息,搜索对已收录的短视频资源将对用户呈现为视频极速体验页。此外,综艺影视类长视频,搜索引擎仅收录页面URL。
转载请注明来源网址:https://www.mubanyun.com/seo/1972.html



 皖公网安备 34010402703520号
皖公网安备 34010402703520号



发表评论
评论列表(条)